Maximum Likelihood Orbit#
This title is something of a bait-and-switch, since jorbit does not contain any self-contained code to “fit” an orbit in a Bayesian sense. It does, however, have the ability to easily evaluate the likelihood of a given state vector compared to a set of observations, the derivative of that likelihood with respect to each component of that state vector, and a wrapper for finding the maximum likelihood state vector using the L-BFGS-B algorithm. Actually computing the posterior distribution of each orbital element is on you: feel free to use your favorite MCMC or nested sampling package!
Below demonstrates some of the functions that might be useful in that process.
import jax
jax.config.update("jax_enable_x64", True)
import jax.numpy as jnp
import astropy.units as u
import matplotlib.pyplot as plt
from astropy.coordinates import SkyCoord
from astropy.time import Time
from astroquery.jplhorizons import Horizons
from jorbit import Particle, Observations
from jorbit.data.constants import SPEED_OF_LIGHT
from jorbit.utils.states import KeplerianState, CartesianState
First, let’s use Horizons to generate some fake obersvations of an asteroid:
nights = [Time("2025-01-01 07:00"), Time("2025-01-02 07:00"), Time("2025-01-05 07:00")]
times = []
for n in nights:
times.extend([n + i * 1 * u.hour for i in range(3)])
times = Time(times)
obj = Horizons(id="274301", location="695@399", epochs=times.utc.jd)
pts = obj.ephemerides(extra_precision=True, quantities="1")
coords = SkyCoord(pts["RA"], pts["DEC"], unit=(u.deg, u.deg))
times = Time(pts["datetime_jd"], format="jd", scale="utc")
fig, ax = plt.subplots()
ax.scatter(coords.ra.deg, coords.dec.deg, marker="x")
ax.invert_xaxis()
Now we can use those to create an Observations object:
obs = Observations(
observed_coordinates=coords,
times=times,
observatories="kitt peak",
astrometric_uncertainties=1 * u.arcsec,
)
This pre-computes the appropriate covariance matrices of the observations and caches the barycentric positions of the observer according to Horizons. Note that all of the likelihood calculations within Particle are built on the assumption that the observer’s position is known exactly, and that the planets/major asteroids are exactly where Horizons says they are.
Let’s now create a Particle object with the “correct” underlying state according to Horizons:
obj = Horizons(id="274301", location="500@0", epochs=times.tdb.jd[0])
vecs = obj.vectors(refplane="earth")
true_x0 = jnp.array([vecs["x"], vecs["y"], vecs["z"]]).T[0]
true_v0 = jnp.array([vecs["vx"], vecs["vy"], vecs["vz"]]).T[0]
p_true = Particle(
x=true_x0, v=true_v0, time=times[0], name="274301 Wikipedia", observations=obs
)
Since we’re only looking at a very short arc here, we likely don’t need the most complicated dynamical model or the most accurate integrator available in jorbit. To avoid unnecessary computation, and speed things up, let’s see what combinations we can get away with. First, let’s get a baseline ephemeris using our most accurate options, which are jorbit’s defaults: the IAS15 integrator and the “default solar system” gravity model that includes relativistic corrections for the planets and the Newtonian influence of the largest asteroids.
eph_accurate = p_true.ephemeris(times, observer="kitt peak")
eph_accurate
<SkyCoord (ICRS): (ra, dec) in deg
[(153.71884036, 3.87806272), (153.71699894, 3.87809774),
(153.7150971 , 3.87813451), (153.67551789, 3.87997832),
(153.67340318, 3.88013519), (153.67122869, 3.88029376),
(153.50691519, 3.90343399), (153.50398273, 3.90396148),
(153.50099271, 3.90449052)]>
Let’s now compare this ephemeris to one created with a simpler setup: the Y4 integrator (a 4th-order symplectic integrator from Yoshida 1990) and the “newtonian planets” gravity model that includes only Newtonian influences from the Sun and planets:
p_test = Particle(
x=true_x0,
v=true_v0,
time=times[0],
name="274301 Wikipedia",
observations=obs,
integrator="Y4",
max_step_size=3 * u.day,
gravity="newtonian planets",
)
eph_test = p_test.ephemeris(times, observer="kitt peak")
eph_test.separation(eph_accurate).to(u.arcsec)
Since the differences here are well below our observational uncertainties, we can be confident that this simpler setup is sufficient. Note though that appropriate intergrator (and the maximum step size, if you need to set one) will depend on the specifics of your problem, including the timespan of your observations, the orbit of the object, and the desired accuracy. Always be sure to test different configurations to ensure that your results are robust!
Moving forwards, let’s create a Particle object that uses this simpler integrator and gravity model, but is slightly perturbed from the true state:
p_perturbed = Particle(
x=true_x0 + jnp.ones(3) * 1e-1, # shift by a tenth of an AU
v=true_v0 - jnp.ones(3) * 1e-3, # shift by 1e-3 AU/day (~1.7 km/s)
time=times[0],
name="274301 Perturbed",
observations=obs,
integrator="Y4",
max_step_size=3 * u.day,
gravity="newtonian planets",
)
The astrometric residuals between this perturbed orbit and the observations are pretty terrible:
p_perturbed.residuals(p_perturbed.cartesian_state)
Array([[-13872.58541455, 10651.54202904],
[-13870.07372756, 10649.46983666],
[-13867.55034093, 10647.38404358],
[-13810.06565545, 10600.24904546],
[-13807.48859604, 10598.11487543],
[-13804.89944235, 10595.96689262],
[-13612.7556172 , 10437.29358088],
[-13609.96752458, 10434.96435893],
[-13607.1661787 , 10432.62073379]], dtype=float64)
Note that the above are sky-plane residuals in arcseconds- well over a degree off!
We can take a look at the differences between these particles by examining their orbital elements:
print(p_true._keplerian_state, end="\n\n")
print(p_perturbed._keplerian_state)
KeplerianState(semi=Array([2.37859645], dtype=float64), ecc=Array([0.14924503], dtype=float64), inc=Array([6.73363597], dtype=float64), Omega=Array([183.37294141], dtype=float64), omega=Array([140.26387023], dtype=float64), nu=Array([173.6546239], dtype=float64), acceleration_func_kwargs={'c2': 29979.063823897617}, time=Array(2460676.79246741, dtype=float64))
KeplerianState(semi=Array([3.3054992], dtype=float64), ecc=Array([0.17673654], dtype=float64), inc=Array([3.87846549], dtype=float64), Omega=Array([208.08713233], dtype=float64), omega=Array([306.18499065], dtype=float64), nu=Array([339.74157202], dtype=float64), acceleration_func_kwargs={'c2': 29979.063823897617}, time=Array(2460676.79246741, dtype=float64))
The highest-level built in function that’s relevant here is max_likelihood, which will create a new Particle object that’s represents maximum likelihood of the observations:
p_best_fit = p_perturbed.max_likelihood(verbose=True)
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 6 M = 100
At X0 0 variables are exactly at the bounds
At iterate 0 f= 3.07889D+02 |proj g|= 5.53857D+06
At iterate 1 f= 2.31464D+02 |proj g|= 3.66557D+06
At iterate 2 f= 1.87597D+02 |proj g|= 3.28397D+06
At iterate 3 f= 1.65411D+01 |proj g|= 6.61463D+03
At iterate 4 f= 1.65411D+01 |proj g|= 9.44025D+00
At iterate 5 f= 1.65411D+01 |proj g|= 6.98074D+00
At iterate 6 f= 1.65411D+01 |proj g|= 6.92898D+00
At iterate 7 f= 1.65411D+01 |proj g|= 2.16979D+01
At iterate 8 f= 1.65411D+01 |proj g|= 3.46305D+01
At iterate 9 f= 1.65411D+01 |proj g|= 5.00808D+01
At iterate 10 f= 1.65411D+01 |proj g|= 6.90081D+01
At iterate 11 f= 1.65411D+01 |proj g|= 1.01806D+02
At iterate 12 f= 1.65411D+01 |proj g|= 1.54151D+02
At iterate 13 f= 1.65411D+01 |proj g|= 2.38962D+02
At iterate 14 f= 1.65411D+01 |proj g|= 3.74701D+02
At iterate 15 f= 1.65411D+01 |proj g|= 5.89152D+02
At iterate 16 f= 1.65411D+01 |proj g|= 9.13684D+02
At iterate 17 f= 1.65410D+01 |proj g|= 1.35116D+03
At iterate 18 f= 1.65410D+01 |proj g|= 1.76378D+03
At iterate 19 f= 1.65410D+01 |proj g|= 1.72806D+03
At iterate 20 f= 1.65409D+01 |proj g|= 2.14543D+03
At iterate 21 f= 1.65409D+01 |proj g|= 9.20343D+02
At iterate 22 f= 1.65409D+01 |proj g|= 3.75016D+02
At iterate 23 f= 1.65409D+01 |proj g|= 1.15536D+02
At iterate 24 f= 1.65409D+01 |proj g|= 1.05303D+01
At iterate 25 f= 1.65409D+01 |proj g|= 3.16794D-01
At iterate 26 f= 1.65409D+01 |proj g|= 1.65841D-02
At iterate 27 f= 1.65409D+01 |proj g|= 1.63096D-02
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
6 27 36 1 0 0 1.631D-02 1.654D+01
F = 16.540895415063563
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
This problem is unconstrained.
Qualitatively, we can see how well this worked by again examining the orbital elements:
print(p_true._keplerian_state, end="\n\n")
print(p_best_fit._keplerian_state)
KeplerianState(semi=Array([2.37859645], dtype=float64), ecc=Array([0.14924503], dtype=float64), inc=Array([6.73363597], dtype=float64), Omega=Array([183.37294141], dtype=float64), omega=Array([140.26387023], dtype=float64), nu=Array([173.6546239], dtype=float64), acceleration_func_kwargs={'c2': 29979.063823897617}, time=Array(2460676.79246741, dtype=float64))
KeplerianState(semi=Array([2.37724581], dtype=float64), ecc=Array([0.14982426], dtype=float64), inc=Array([6.73732954], dtype=float64), Omega=Array([183.34436234], dtype=float64), omega=Array([139.77676519], dtype=float64), nu=Array([174.17179084], dtype=float64), acceleration_func_kwargs={'c2': 29979.063823897617}, time=Array(2460676.79246741, dtype=float64))
Quantitatively, we can see how well this worked by examining the residuals and likelihoods:
res_true = p_true.residuals(p_true._keplerian_state)
res_perturbed = p_perturbed.residuals(p_perturbed._keplerian_state)
res_best_fit = p_best_fit.residuals(p_best_fit._keplerian_state)
fig, ax = plt.subplots()
ax.scatter(res_true[:, 0] * 1e3, res_true[:, 1] * 1e3, label="True")
ax.scatter(res_best_fit[:, 0] * 1e3, res_best_fit[:, 1] * 1e3, label="Best Fit")
w = 2
ax.set(
xlim=(-w, w),
ylim=(-w, w),
aspect="equal",
xlabel="RA Residual (mas)",
ylabel="Dec Residual (mas)",
)
ax.legend()
<matplotlib.legend.Legend at 0x1363170e0>
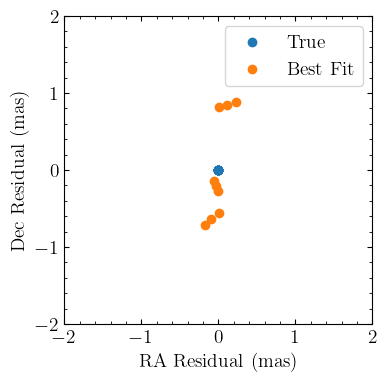
Naturally if we had added noise to the observations the residuals wouldn’t be this small, but it’s reassuring that we can go from $>$ degree errors to sub-arcsecond residuals without too much trouble.
Next let’s take a look at the likelihoods:
print(f"p_true: {p_true.loglike(p_true._keplerian_state)}")
print(f"p_perturbed: {p_perturbed.loglike(p_perturbed._keplerian_state)}")
print(f"p_best_fit: {p_best_fit.loglike(p_best_fit._keplerian_state)}")
p_true: -16.540893597690314
p_perturbed: -1354314046.2250638
p_best_fit: -16.54089541506363
This confirms that our max_likelihood function is doing what we expect: increasing the loglikelihood to about as high as it can go.
This gives us an excuse to consider the loglike function some more. It will compute the log likelihood of either a given KeplerianState or CartesianState without modifying the actual particle’s state:
test_kep_state = KeplerianState(
semi=jnp.array([2.37859645]),
ecc=jnp.array([0.14924503]),
inc=jnp.array([6.733637]),
Omega=jnp.array([183.37294715]),
omega=jnp.array([140.26386151]),
nu=jnp.array([173.65462561]),
time_reference=2460676.792467407,
acceleration_func_kwargs={"c2": SPEED_OF_LIGHT**2},
)
p_true.loglike(test_kep_state)
Array(-16.54123861, dtype=float64)
test_cart_state = test_kep_state.to_cartesian()
test_cart_state
CartesianState(x=Array([[-2.00572342, 1.77860129, 0.51974071]], dtype=float64), v=Array([[-0.00665991, -0.00662871, -0.00203885]], dtype=float64), acceleration_func_kwargs={'c2': 29979.063823897617}, time=2460676.792467407)
p_true.loglike(test_cart_state)
Array(-16.54123861, dtype=float64)
The neat thing is, since all of this is in JAX, we can compute the derivative of the likelihood with respect to each of the components of these states through the magic of automatic differentiation:
print(jax.grad(p_true.loglike)(test_kep_state), end="\n\n")
print(jax.grad(p_true.loglike)(test_cart_state))
KeplerianState(semi=Array([-1600.19856592], dtype=float64), ecc=Array([-3339.26674918], dtype=float64), inc=Array([-186.49111382], dtype=float64), Omega=Array([253.25431965], dtype=float64), omega=Array([276.47536713], dtype=float64), nu=Array([275.24157677], dtype=float64), acceleration_func_kwargs={'c2': Array(5.03221365e-14, dtype=float64)}, time=Array(-52.50645197, dtype=float64))
CartesianState(x=Array([[-2957.00737826, -6534.91897721, 3720.84451676]], dtype=float64), v=Array([[ -5136.22541064, -11301.35754683, 6410.96194942]], dtype=float64), acceleration_func_kwargs={'c2': Array(5.03221365e-14, dtype=float64)}, time=Array(-52.50645197, dtype=float64))
This is pretty cool! This is the true gradient propagated all the way through our dynamical model and numerical integrator; since we used p_true, that means this is accounting for all of the predictor-corrector iterations of IAS15 and all of the convergent iterations of the PPN-gravity function. Note that since we use jax.while loops in parts of the model, we can’t use reverse-mode autodiff: even when you call jax.grad, it’s really doing forward-mode autodiff via a custom_vjp.
Finally, for convenience, we also include a function that takes simple 1D arrays as inputs, which might be easier if using fitters like emcee or dynesty. These 1D arrays assume the first 3 elements are the barycentric ICRS x, y, and z positions in AU, and the next 3 are the barycentric ICRS x, y, and z velocities in AU/day. Note that the signs here are flipped: we assume that they’re “objective” functions to be minimized rather than “log likelihoods” to be maximized.
one_d = jnp.concatenate([test_cart_state.x.flatten(), test_cart_state.v.flatten()])
one_d
Array([-2.00572342, 1.77860129, 0.51974071, -0.00665991, -0.00662871,
-0.00203885], dtype=float64)
print(p_true.scipy_objective(one_d))
print(p_true.scipy_objective_grad(one_d))
16.541238608655657
[ 2957.00737826 6534.91897721 -3720.84451676 5136.22541064
11301.35754683 -6410.96194942]